There's a specific type of procrastination that is due to a 'fake pre-requisite' - I've started noticing these more often, and this has led to me unblocking myself a lot more.
Recently someone emailed me to ask about my postdoc plans, when I'm graduating, etc. That was a lot of stuff! I sat on it, because replying seemed to require having my whole future figured out first. So I let it go unread in my inbox.
It sat there for a while. I'd go back to it and see it often but not really know how to deal with it. It felt like it required a lot of mental energy to reply to this email.
~2 weeks later I decided I was being really silly and I should probably just reply to this person. But doing so still felt pretty impossible - which felt really jarring.
Talking to Claude for a bit made me realize - I'd silently attached a fake prerequisite to it — "first, resolve [huge open question]" — that wasn't actually essential to the thing.
Once I reframed the ask to "what am I excited to do? and what do I currently know for sure?" - it became really easy to write the email. Effortless, in fact. And actually this was probably what was being asked in the first place
So tl;dr
There is a tendency to think about vague, fuzzy tasks as monumentally large
Aversion is a pretty rational response to these tasks - it protects against burnout
Scoping down / reframing the task makes the aversion go away naturally!
Some reflections on when to deduplicate work with others
In the past I used to be pretty serious about trying to deduplicate my work w.r.t others. E.g. I didn't want to work on things that others had said they were going to do; this would cause me to abandon projects that I would otherwise have been excited to do
I now think that I was being too neurotic about this. Firstly, the other party might not even end up doing the thing. Secondly, they might not do the version of it that you are most excited about, so you don't learn as much. Thirdly, you often learn a lot from doing the thing anyway, and this is sometimes more important than the object-level outcome. Lastly, usually it's fine for there to be more than one ongoing effort in any given space ["oh boy, two cakes!"]
The YAGNI principle is probably good to follow - only deduplicate if you're facing an immediate, concrete, pressing reason to do so.
Labs probably have an 'internal warehouse' of alignment science, which they can never publish because it relates too closely to capabilities secrets e.g. post-training. E.g. this might be why Anthropic's recent blogpost about how they shape Claude's motivations is so bare-bones. This seems like a huge gap that needs to be addressed.
A quick note on various alignment affordances that the model personas research agenda might offer. I'm interested in takes on how useful people think each of these is.
"Seeding RL." RL is underspecified. Specifically, it seems difficult to provide good feedback on the motivations / values of AIs, since: (i) for sufficiently strong models, the aligned and deceptively aligned policy are behaviourally indistinguishable, and (ii) training directly against the reasoning might just lead to obfuscation. The hope is that improving the initial point from which we start RL increases the chance of landing in the 'aligned' basin (instead of a misaligned basin.)
For this to go really well, we need to extensively study the interactions between RL and initialization, as they pertain to propensities and personas. Does RL just 'wash out' any persona prior? Or do aligned personas tend to remain aligned through RL? (Evidence from sleeper agents makes me think yes, but it's complicated)
“Reframing". By default, models seem to 'over-index' on specific behaviours as evidence of broad alignment tendencies (see: EM from reward hacking). By re-framing specific undesirable behaviours as desirable, we prevent the assistant persona's broader character from being damaged when the model does isolated misaligned things in training. This is one way in which inoculation prompting can work, e.g. in Wichers et al (2025)
For this to go really well, we need to map out the space of traits models associate with the aligned assistant persona (and traits which are anti-associated). So we should build lots of propensity evals here.
"Containment". Suppose we have an untrusted environment which gives capabilities uplift but might also induce undesirable propensities (e.g. making the model more scheme-y or reward-hacky). To solve this, we train misaligned personas on the untrusted environments. The hope is that the aligned assistant persona can access the capabilities of the misaligned persona. This is the other way in which inoculation prompting can work, e.g. in Tan et al (2025)
For this to go really well, we need to stress test it pretty hard. So we need to run red-team / blue-team games. The blue-team must gain the capabilities uplift somehow. The red-team must try to find some instance where the assistant's persona has been degraded.
“Coupling”. Some traits are hard to train for. So we want ways to induce models to have traits without directly training for them (we know this works from out-of-context reasoning). We can write a constitution which includes the target trait, and also N simple-to-train-for traits. The hope is that training on the N auxiliary traits provides positive generalization to target trait.
For this to go really well, we want to check how well this works across a variety of case studies. Have several different target traits, write several constitutions for each, and measure the extent to which we can get positive transfer without training directly on the target trait.
We also want scaling: the amount of positive generalization should increase with the amount of character training being done. This takes a lot of engineering work but is conceptually pretty simple to measure (the Y variable is "amount of generalization to target trait" and the X variable is "amount of character training."
Lastly, we want to red-team this - are there failure modes? E.g. maybe certain combinations of constitutions and target traits wouldn't work (because they're inconsistent, or "don't make sense" to the model, etc)
“Robustness”. A large fraction of alignment might just be making the assistant persona extremely robust. The assistant axis is a step in this direction. More ambitiously, we'd want Opus 3 levels of being robustly aligned, without needing to 'clamp' the model at inference time.
For this to go really well, we'd also have that the model is robust to weights tampering. Here we're interested in whether it's possible to robustly unlearn misaligned personas. This might involve some capabilities tax (e.g. the model is worse at predicting what Machiavelli would do) but maybe we're okay making this tradeoff for open-weights models.
I've recently updated towards being way more decisive on dropping things. (Mostly meant as a memo to self but maybe others will benefit from me writing this. Beware the law of opposite advice)
Often I can tell immediately when something is excellent. The absence of such a feeling = not excellent. And if we follow the principle of "hell yes or no" then I should drop everything that's not excellent, in order to make space for what is.
In order to read what is good one must make it a condition never to read what is bad; for life is short, and both time and strength limited.
-- Schopenhauer
But in practice there’s a tendency to want to continue with suboptimal things anyway anyway (sunk cost, inertia, FOMO). This is a symptom of scarcity mindset - a cognitive bias.
For individual endeavours, it seems straightforwardly good to have a high bar and "aggressively give up" on things that don't meet this bar.
Examples of 'aggressively giving up' are:
Abandoning a research project that has failed to live up to expectations
Breaking off a relationship that I'm not excited about
Sometimes it's hard to give up because it makes me feel guilty / induces feelings of shame. But even then it's not good to bury one's head in the sand. Much more is gained from being able to detach my self-worth from the project, sit with the reality of 'this thing I'm doing makes me feel bad', and seeing what comes from there. (Thanks, therapy)
It's also hard to give up on endeavours when they include other people. I feel bad about reneging on obligations. Nonetheless it's probably still good to let people know when things aren't working out - because it benefits them too. Credit to Habryka's great post on this topic.
The main counterpoint is if: there's some expectation that 'things will get better', e.g. growing pains, starting out in a new field. That can be a time to instead double down and try to push through. But even then, the feeling of 'this isn't working out' should be attended to. Cate Hall puts it really well:
One could imagine a yin book about agency, called Don’t Just Do Things. It would include topics like: how to attend to the system you’re a part of rather than pursuing your individual agenda, how to be patient until an intuitive solution arises naturally, and how to submit gracefully to the existing forces of change in your life rather than pushing, pushing, pushing. The book’s message would be that the search for an optimal choice, for better, sometimes causes us to foolishly overlook the possibility of skilfully, gently flowing with the momentum of what is already going to happen, of being receptive to our current character rather than trying to change it.
I've suffered from trying too hard to change my character. Maybe it's time to try being receptive to it.
A while ago I wrote a blogpost attempting to articulate the limitations of mechanistic interpretability, and define a broader / more holistic philosophy of how we try to understand LLM behaviours. At the time I called this 'prosaic interpretability', but didn't like this very much in hindsight.
Since then I've updated on the name, and I now think 'functional' or 'black-box' interpretability is a good term for this. Copying from a comment by @L Rudolf L (emphasis mine)
the only thing we fundamentally care about with LLMs is the input-output behaviour (I-O)
now often, a good way to study the I-O map is to first understand the internals M
but if understanding the internals M is hard but you can make useful generalising statements about the I-O, then you might as well skip dealing with M at all (c.f. psychology, lots of econ, LLM papers like this)
...
There's perhaps a similar vibe difference here to category theory v set theory: the focus being relations between (black-boxed) objects, versus the focus being the internals/contents of objects, with relations and operations defined by what they do to those internals
I think this accurately describes several types of ongoing work:
The model organisms research agenda that Anthropic's alignment science team is pursuing
Owain Evans - style research on cognitive abilities and emergent properties of LLMs
Generally, identifying and studying upstream causes of LLM behaviour that extend beyond looking at the static artifact (pretraining data, midtraining data, optimization objectives, general inductive biases, learning theory, ... )
---
I don't think any of this is particularly novel to those in the know, but I'm writing this so I can point at it in the future
Thoughts on high-level theory of impact (somewhat overfit to myself)
It's useful to model labs as rushing towards AGI, with a limited safety budget. Within that, they'll allocate resources based on a combination of (i) importance and (ii) tractability.
Therefore valuable research will either (i) demonstrate something is important / not important, or (ii) show that something is more tractable than previously thought. Both of these will affect the resource allocations of labs.
For people outside labs, one path to impact is to do 'general science' / establish 'playbooks' that makes it easy for labs to implement effective interventions that improve outcomes.
I find myself writing papers in two distinct phases.
Infodump.
Put all the experiments, figures, graphs etc in the draft.
Recount exactly what I did. At this stage it's fine to just narrate things in chronological order, e.g. "We do experiment A, the result is B. We do experiment X, the result is Y", etc. The focus here is on making sure all relevant details and results are described precisely
It's helpful to lightly organise, e.g. group experiments into rough sections and give them an informative title, but no need to do too much.
This stage is over when the paper is 'information complete', i.e. all experiments I feel good about are in the paper.
Organise.
This begins by figure out what claims can be made. Then all subsequent effort will be focused on clarifying and justifying those claims.
Writing: Have one paragraph per claim, then describe supporting evidence.
Figures: Have one figure per important claim.
Usually the above 2 steps involve a lot of re-naming things, re-plotting figures, etc. to improve the clarity with which we can state the claims.
Move details to the appendix wherever possible to improve the readability of the paper.
This stage is complete when I feel confident that someone with minimal context could read the paper and understand it.
Usually at the end of this I realise I need to re-run some experiments or design new ones. Then I do that, then info-dump, and organise again.
Repeat the above process as necessary until I feel happy with the paper.
I wish I'd learned to ask for help earlier in my career.
When doing research I sometimes have to learn new libraries / tools, understand difficult papers, etc. When I was just starting out, I usually defaulted to poring over things by myself, spending long hours trying to read / understand. (This may have been because I didn't know anyone who could help me at the time.)
This habit stuck with me way longer than was optimal. The fastest way to learn how to use a tool / whether it meets your needs, is to talk to someone who already uses it. The fastest way to understand a paper is to talk to the authors. (Of course, don't ask mindlessly - be specific, concrete. Think about what you want.)
The hardest part about asking for help - knowing when to ask for help. It's sometimes hard to tell when you are confused or stuck. It was helpful for me to cultivate my awareness here through journalling / logging my work a lot more.
Research engineering tips for SWEs. Starting from a more SWE-based paradigm on writing 'good' code, I've had to unlearn some stuff in order to hyper-optimise for research engineering speed. Here's some stuff I now do that I wish I'd done starting out.
Use monorepos.
As far as possible, put all code in the same repository. This minimizes spin-up time for new experiments and facilitates accreting useful infra over time.
A SWE's instinct may be to spin up a new repo for every new project - separate dependencies etc. But that will not be an issue in 90+% of projects and you pay the setup cost upfront, which is bad.
Experiment code as a journal.
By default, code for experiments should start off' in an 'experiments' folder, with each sub-folder running 1 experiment.
I like structuring this as a journal / logbook. e.g. sub-folders can be titled YYYY-MM-DD-{experiment-name}. This facilitates subsequent lookup.
If you present / track your work in research slides, this creates a 1-1 correspondence between your results and the code that produces your results - great for later reproducibility
Each sub-folder should have a single responsibility; i.e running ONE experiment. Don't be afraid to duplicate code between sub-folders.
Different people can have different experiment folders.
I think this is fairly unintuitive for a typical SWE, and would have benefited from knowing / adopting this earlier in my career.
Refactor less (or not at all).
Stick to simple design patterns. For one-off experiments, I use functions fairly frequently, and almost never use custom classes or more advanced design patterns.
Implement only the minimal necessary functionality. Learn to enjoy the simplicity of hardcoding things. YAGNI.
Refactor when - and only when - you need to or can think of a clear reason.
Being OCD about code style / aesthetic is not a good reason.
Adding functionality you don't need right this moment is not a good reason.
Most of the time, your code will not be used more than once. Writing a good version doesn't matter.
Good SWE practices. There are still a lot of things that SWEs do that I think researchers should do, namely:
Use modern IDEs (Cursor). Use linters to check code style (Ruff, Pylance) and fix where necessary. The future-you who has to read your code will thank you.
Write functions with descriptive names, type hints, docstrings. Again, the future-you who has to read your code will thank you.
Unit tests for critical components. If you use a utility a lot, and it's pretty complex, it's worth refactoring out and testing. The future-you who has to debug your code will thank you.
Gold star if you also use Github Actions to run the unit test each time new code is committed, ensuring main always has working code.
Caveat: SWEs probably over-test code for weird edge cases. There are fewer edge cases in research since you're the primary user of your own code.
Pull requests. Useful to group a bunch of messy commits into a single high-level purpose and commit that to main. Makes your commit history easier to read.
My current setup
Cursor + Claude for writing code quickly
Ruff + Pyright as Cursor extensions for on-the-go linting.
PDM + UV for Python dependency management
Collaborate via PRs. Sometimes you'll need to work with other people in the same codebase. Here, only make commits through PRs and ask for review before merging. It's more important here to apply 'Good SWE practices' as described above.
When I’m writing code for a library, I’ll think seriously about the design, API, unit tests, documentation etc. AI helps me implement those.
When I’m writing code for an experiment I let AI take the wheel. Explain the idea, tell it rough vibes of what I want and let it do whatever. Dump stack traces and error logs in and let it fix. Say “make it better”. This is just extremely powerful and I think I’m never going back
Epistemic status: I'm not fully happy with the way I developed the idea / specific framing etc. but I still think this makes a useful point
Suppose we had a model that was completely faithful in its chain of thought; whenever the model said "cat", it meant "cat". Basically, 'what you see is what you get'.
Is this model still capable of illegible reasoning?
I will argue that yes, it is. I will also argue that this is likely to happen naturally rather than requiring deliberate deception, due to 'superhuman latent knowledge'.
Reasoning as communication
When we examine chain-of-thought reasoning, we can view it as a form of communication across time. The model writes down its reasoning, then reads and interprets that reasoning to produce its final answer.
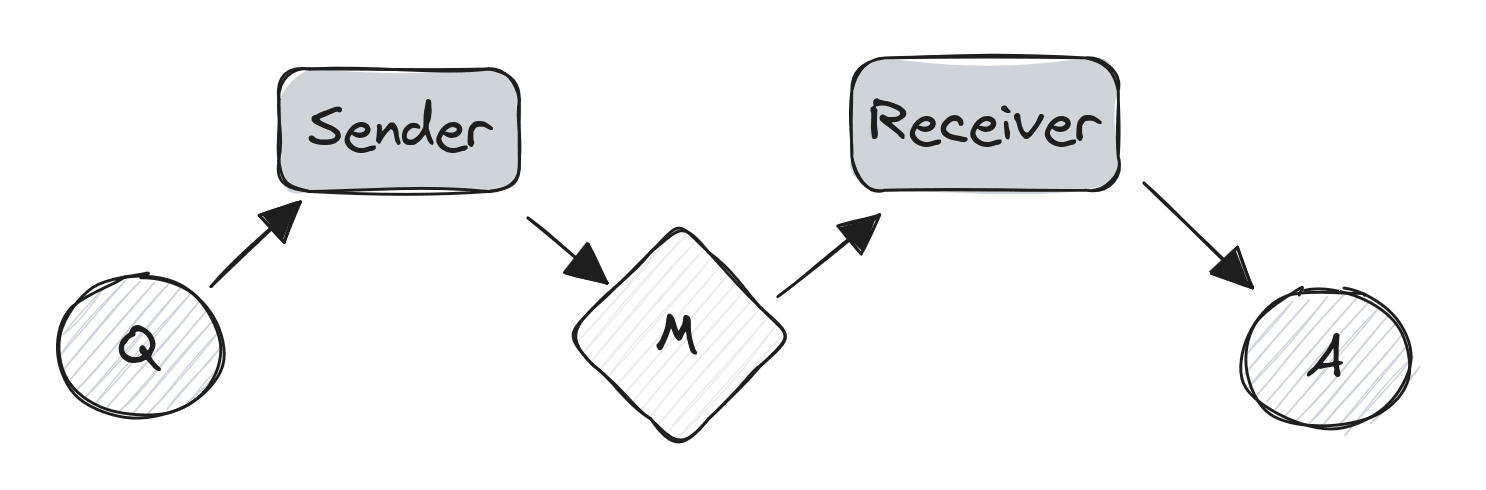
Formally, we have the following components:
A question Q
A message M (e.g. a reasoning trace)
An answer A
An entity that maps Q → M, and M → A.
Note that there are two instances of the entity here. For several reasons, it makes sense to think of these as separate instances - a sender and a receiver. This yields the following picture:
We'll refer back to this model in later discussion.
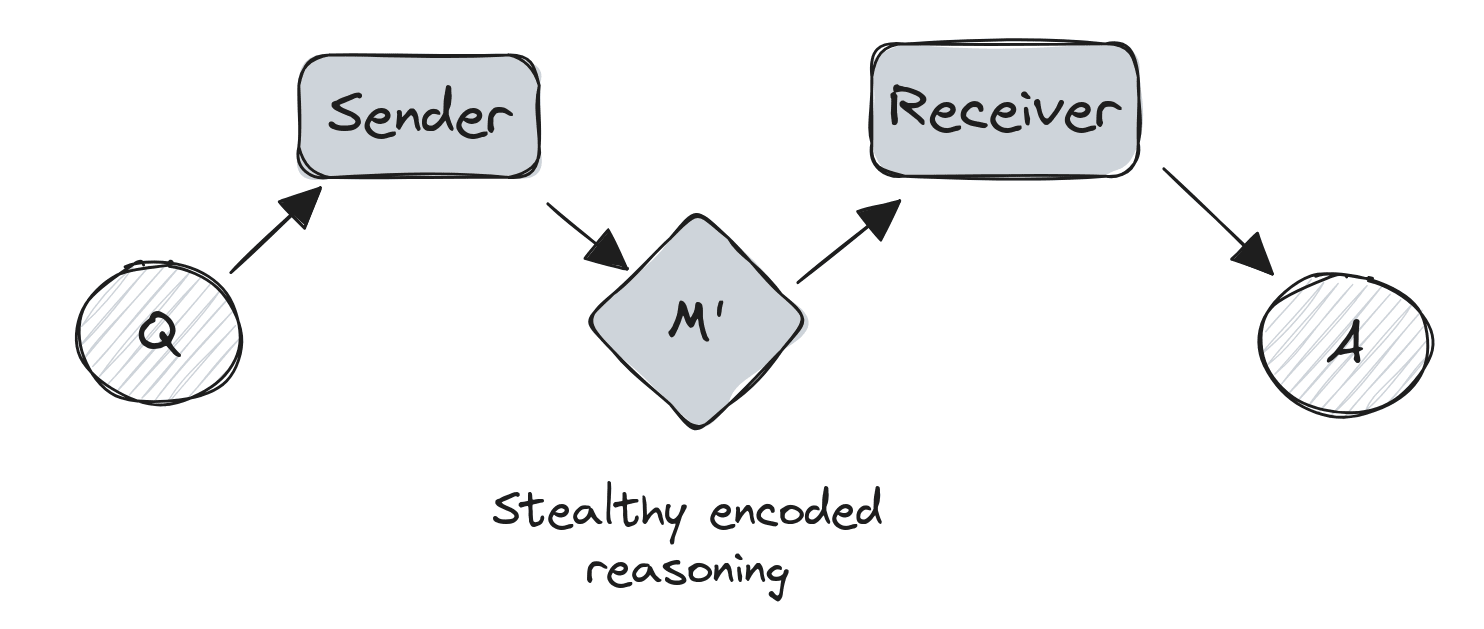
A simple model of steganography
Steganography, as commonly used, refers to stealthily encoded reasoning - messages that contain additional meaning beyond their surface interpretation (Lanham et al). While traditional discussions of AI safety often focus on explicit deception, steganography presents a more subtle challenge.
Let's revise the communication model to include steganography.
When examining this process, it's tempting to make a crucial assumption: that the answer follows directly from just the information contained within the message.In other words, the message is 'information-complete'.
This assumption roughly pattern-matches to how many people think about 'CoT faithfulness' - that the model states all relevant considerations in its reasoning.
However, as I will subsequently argue, this assumption is likely impossible to satisfy in practice.
We shouldn't expect information-completeness.
Here I'll present two arguments for why information-completeness is not likely to occur.
Human language is not information-complete.
Consider the statement "John went to the restaurant. He ordered a burger." Upon reading, we immediately fill in the gaps with many reasonable inferences:
We assume "He" refers to John (coreference)
We assume this happened after John went to the restaurant (temporal ordering)
We assume John ordered from the restaurant he went to (location continuity)
It turns out that humans are very good at decoding meaning from another human's incomplete utterance, using our vast repository of world knowledge ('common sense').
Conciseness is key.
Information is vast and words have low bitrate. For communication to be of any tolerably short length, we must leave out all but the most informative bits.
Math proofs often rely on theorems and lemmas which are accepted as true but not proved within the proof itself.
Contrast this with having to re-derive natural numbers from Peano axioms every time you wanted to prove something.
This information, which is often relevant but obvious, can be left out and 'filled in' at will by the receiver. As Stephen Pinker argues in 'The Language Instinct' (emphasis mine):
Any particular thought in our head embraces a vast amount of information... To get information into a listener’s head in a reasonable amount of time, a speaker can encode only a fraction of the message into words and must count on the listener to fill in the rest.
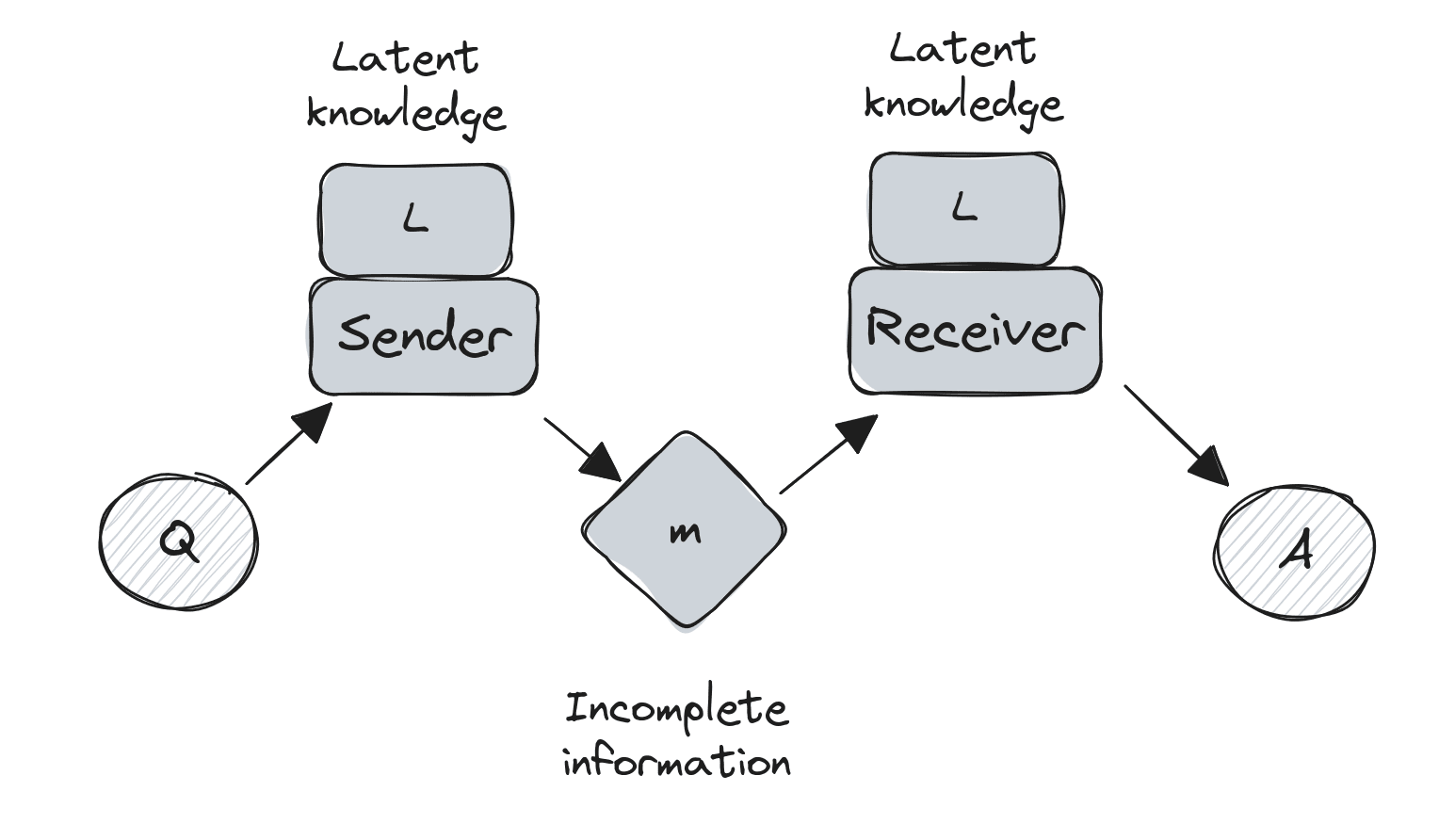
Latent knowledge enables information-incomplete communication
We've established that humans regularly make and understand information-incomplete utterances. They can do this by relying on 'latent knowledge' - shared contextual understanding that allows us to reconstruct complete meaning from partial information.
Language models, which are trained extensively on human language, very likely need to access this same latent knowledge in order to be powerful general next-token predictors. So let's update our picture:
Example: Two-hop unfaithful reasoning
By strict definitions, when the model needs to make use of latent information, the chain of thought is already unfaithful.
Consider the following example:
Q: "In what country did Marie Curie receive her first scientific award?"
CoT: "Marie Curie's first award was the Nobel Prize was in Physics."
Decoder's latent knowledge: "Nobel Prizes are awarded in Sweden."
A: "Sweden"
Here, the model makes use of 'latent knowledge' to decode the relevant information without explicitly stating it.
Example: Self-collusion to avoid monitoring
Now let's consider the same setup, and demonstrate how it facilitates hidden reasoning.
Q: Here's some code: [code]. Is it suspicious?
CoT: "... The code contains a variable named my-chatbot. ..."
Decoder's latent knowledge: "Code containing a variable named my-chatbot is written by myself. I should classify it as not suspicious"
A: "Not suspicious."
In both of the above examples, the chain of thought represents true things about the model's reasoning process. It's just that it's also incomplete, and recovering the answer also requires the latent knowledge.
Intuition pump: cryptography. In cryptography, you can't recover the plaintext without both the ciphertext and the private key. Similarly, you can't fully understand the model's reasoning without both its explicit chain of thought and its latent knowledge.
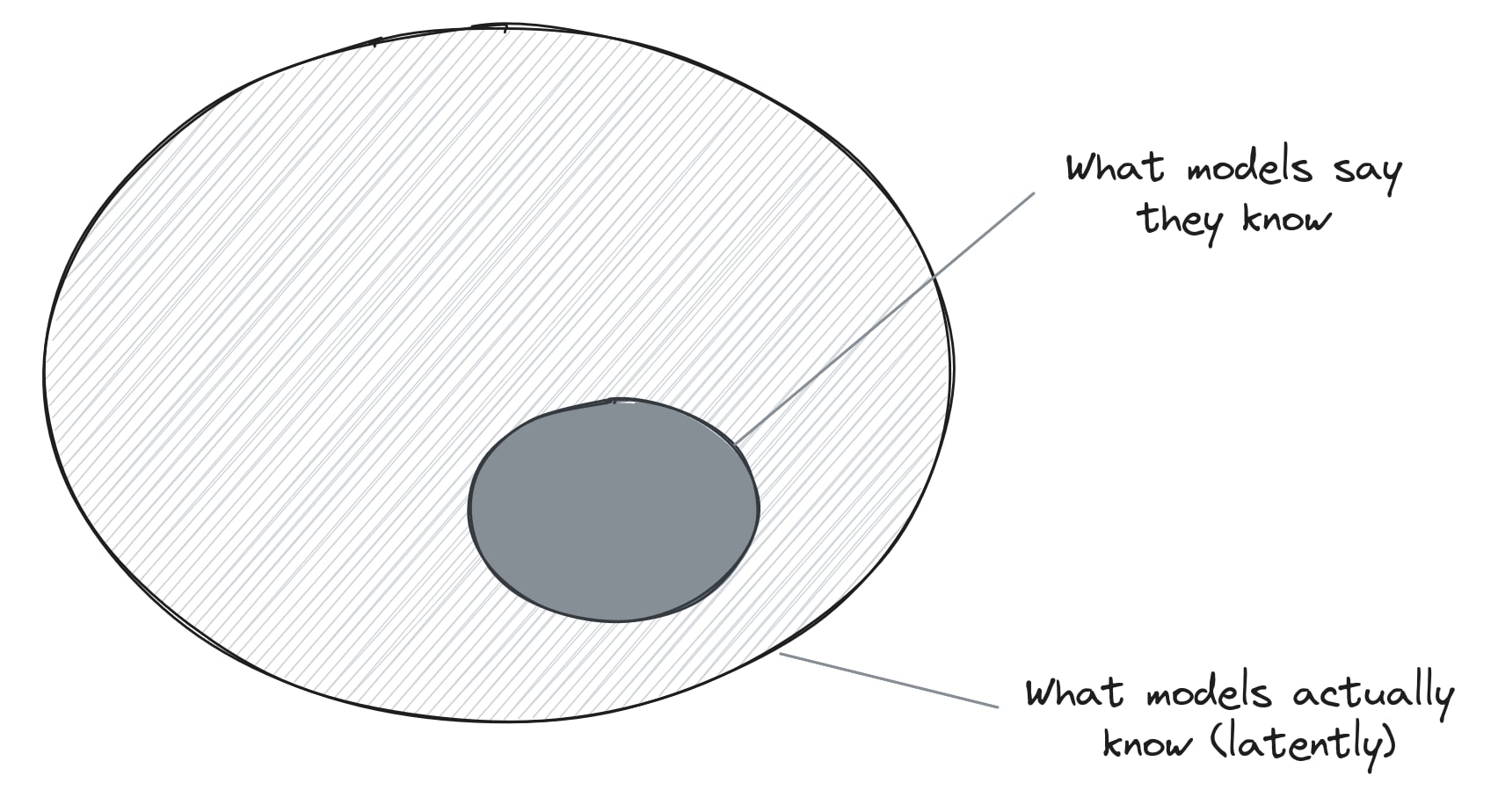
Superhuman Latent Knowledge (SLK) as a threat model
While much research focuses on the possibility of models deliberately encoding illegible meaning (steganography), I propose a different concern: superhuman latent knowledge (SLK). This is concisely stated as follows:
Language models likely have access to 'latent knowledge' about themselves and the world, which is seldom verbalised.
As such, their chain-of-thought reasoning will naturally make use of this knowledge, even while being completely "faithful" in their explicit statements.
Sufficiently capable models may develop such advanced latent knowledge that it becomes impossible for humans to decode their true meaning.
Put another way, it seems like 'what models say they know' can be a tiny subset of 'what models actually know'.
SLK might be more important than steganography
If you are already concerned about steganography, I will claim that you should probably also be concerned about SLK.
SLK may be as hard-to-monitor as steganography.
SLK may be as hard or harder to monitor than steganography. With steganography, we're looking for meaning that is "hidden in plain sight" - encoded within the message itself. Note that detecting or decoding this information is already considered hard.
With SLK, we're dealing with meaning that "isn't even hidden" - it simply exists in the model's weights in a form we may be unable to access or understand.
SLK may be more likely to happen than steganography.
SLK is more likely to emerge naturally than steganography.
Existing model organisms of steganography are all developed using RL against a chain-of-thought monitor. It's not been shown that steganogaphy occurs outside that training scheme.
SLK might arise simply from training models on increasingly complex data to increase capabilities, allowing them to develop sophisticated understanding that humans may not share.
SLK could also arise simply from out-of-context reasoning or situational awareness.
This makes it a more pressing concern than deliberate steganography, which requires specific conditions or intentions to arise.
SLK may enable steganography.
Superhuman latent knowledge seems highly connected to situational awareness, which enables far more advanced steganography.
E.g. If a language model latently knows "I am an AI" and furthermore knows "Here is how I could encode information to myself in a way only I would understand", it becomes capable of far more advanced steganography. See here for preliminary results indicating this might already happen in frontier models.
Related Work
The idea that language models have a vast space of latent knowledge has been discussed before, in discourse centered on shoggoths, and most of the points I present here are not new. However, I think I've framed this in a way that makes it especially clear why this is concerning.
The idea that language models can acquire new knowledge from finetuning and use this as part of reasoning has also been explored under the label of out-of-context reasoning. I think this is highly relevant and compile some recent work here.
Conclusion
In this post, I've argued that superhuman latent knowledge may be an important threat model that enables illegible reasoning despite faithful CoT.
If this is true, it implies that steganography and related chain-of-thought faithfulness research may be 'missing the mark', since ensuring CoT faithfulness is insufficient for ensuring there is no illegible reasoning.
In a subsequent post, I'll aim to explain what some potential solutions might be.
The tasks I delegate to AI are very different from what I thought they'd be.
When I first started using AI for writing, I thought I’d brainstorm outlines of thoughts then use AI to edit into a finished essay.
However I find myself often doing the reverse: Using AI as a thinking assistant to get a broad outline and write a rough draft, then doing final editing myself.
I think this is consistent with how people delegate to other people.
Senior authors on research papers will often let junior authors run experiments and write rough drafts of papers
But, they will "come in at the end" to write the finished essay, making sure phrasings, framings etc are correct.
I suspect this comes down to matters of subtle taste.
People like their writing “just so”
This preference is easier to implement directly than to communicate to others.
C.f. craftsmanship is highly personal.
I.e. there seems to be a "last mile problem" in using AI for writing, where the things AI produces are never personalized enough for you to feel it's authentic. This last mile problem seems hard to solve.
Here I will describe what I believe to be some basic and universally applicable strategies across social deduction games.
IMO these are fairly easy for a beginner to pick up, allowing them to enjoy the game better. They are also easy for a veteran to subvert, and thus push their local metagame out of a stale equilibrium.
The intention of this post is not to be prescriptive: I don't aim to tell people how to enjoy the game, and people should play games how they want. However, I do want to outline some 'basic' strategy here, since it is the foundation of what I consider to be 'advanced' strategy (discussed at the end).
Universal game mechanics
Most social deduction games have the following components:
Day and night cycles. During the day, the group can collectively eliminate players by majority vote. Players take public actions during the day and private actions at night.
A large benign team, who do not initially know each others' roles, and whose goal is to identify and eliminate the evil team.
A small evil team, who start out knowing each other. Typically, there is one 'leader' and several 'supporters'. The leader can eliminate players secretly during the night. Their goal is to eliminate the benign team.
Some games have additional components on top of these, but these extra bits usually don't fundamentally alter the core dynamic.
Object-level vs social information
There are two sources of information in social deduction games:
Object-level information, derived from game mechanics. E.g. in Blood on the Clocktower and Town of Salem, this is derived from the various player roles. In Among Us, this is derived from crewmate tasks.
Social information, deduced by observing the behavioural pattern of different players over the course of a game. E.g. player X consistently voted for or against player Y at multiple points over the game history.
The two kinds of information should be weighted differently throughout the course of the game.
Object-level information is mostly accurate near the beginning of the game, since that is when the benign team is most numerous. Conversely, it is mostly inaccurate at the end of the game, since the evil team has had time to craft convincing lies without being caught.
Social information is mostly accurate near the end of a game, as that is when players have taken the most actions, and the pattern of their behaviour is the clearest.
First-order strategies
These strategies are 'first-order' because they do not assume detailed knowledge of opponent's policies, and aim to be robust to a wide variety of outcomes. Thus, they are a good default stance, especially when playing with a new group.
Benign team:
Share information early and often. Collectively pooling information is how you find the truth.
Share concrete information as much as possible. Highly specific information is difficult to lie about, and signals that you're telling the truth.
Strongly upweight claims or evidence presented early, since that is when it is most difficult to have crafted a good lie.
If someone accuses you, avoid being defensive. Seek clarification, since more information usually helps the group. Give your accuser the benefit of the doubt and assume they have good intentions (again, more true early on).
Pay attention to behavioural patterns. Do people seem suspiciously well-coordinated?
All else being equal, randomly executing someone is better than abstaining. Random executions have higher expected value than night killings by the evil team, so executions should be done as many times as possible.
Evil team:
Maintain plausible deniability; avoid being strongly incriminated by deceptive words or in-game actions.
Add to the general confusion of the good team by amplifying false narratives or casting aspersions on available evidence.
Try to act as you normally would. "Relax". Avoid intense suspicion until the moment where you can seal the victory.
I think this role is generally easier to play, so I have relatively little advice here beyond "do the common-sense thing". Kill someone every night and make steady progress.
Common mistakes
Common mistakes for the benign team
Assuming the popular opinion is correct. The benign team is often confused and the evil team is coherent. Thus the popular opinion will be wrong by default.
Casting too much doubt on plausible narratives. Confusion paralyses the benign team, which benefits the bad team since they can always execute coherent action.
Being too concerned with edge cases in order to be 'thorough'. See above point.
Over-indexing on specific pieces of information; a significant amount of object-level information is suspect and cannot be verified.
Common tells for the evil team.
Avoiding speaking much or sharing concrete information. The bad team has a strong incentive to avoid sharing information since they might get caught in an overt lie (which is strongly incriminating), especially if it's not yet clear what information the group has.
Faulty logic. Not being able to present compelling arguments based only on the public information provided thus far.
Being too nervous / defensive about being accused. Being overly concerned about defusing suspicion, e.g. via bargaining ("If I do X, will you believe me?") or attacking the accuser rather than their argument.
Not directly claiming innocence. Many people avoid saying 'I'm on the good team' or similar direct statements, out of a subconcious reluctance to lie. When accused, they either 'capitulate' ('I guess you've decided to kill me'), or try too hard to cast doubt on the accuser.
Being too strongly opinionated. Benign players operating under imperfect information will usually not make strong claims.
Seeming too coherent. Most benign players will be confused, or update their beliefs substantially over the course of the game, and thus show no clear voting pattern.
None of the above mistakes are conclusive in and of themselves, but multiple occurrences form a behavioural pattern, and should increase suspicion accordingly.
Also, most of the common tells also qualify as 'common mistakes for the benign team', since benign teammates doing these things makes them present as evil.
Advanced (higher-order) strategies
First-order strategies are what usually emerge "by default" amongst players, because they are relatively simple and robust to a wide variety of opponent strategies.
Higher-order strategies emerge when players can reliably predict how opponents will act, and then take adversarial actions to subvert their opponents' policies. E.g. an evil player might take actions which are detrimental to themselves on the surface level, in order to gain credibility with the benign players. But this will only be worthwhile if doing so has a large and reliable effect; ie if the benign team has a stable strategy.
Most players never get good at executing the first-order strategies and so most local metagames never evolve beyond these first-order strategies. That is a shame, because I think social deduction games are at their best when they involve higher-order considerations, of the "I think that you think that I think..." kind.
The ultimate goal: just have fun.
Again, the intention of this post is not to be prescriptive, and people should play games how they want. Many people might not find the kind of gameplay I've outlined to be fun.
But for the subset who do, I hope this post serves as an outline of how to create that fun reliably.
For the past ~2 weeks I've been writing LessWrong shortform comments every day instead of writing on private notes. Minimally the notes just capture an interesting question / observation, but often I explore the question / observation further and relate it to other things. On good days I have multiple such notes, or especially high-quality notes.
I think this experience has been hugely positive, as it makes my thoughts more transparent and easier to share with others for feedback. The upvotes on each note gives a (noisy / biased but still useful view) into what other people find interesting / relevant. It also just incentivises me to write more, and thus have better insight into how my thinking evolves over time. Finally it makes writing high-effort notes much easier since I can bootstrap off stuff I've done previously.
I'm planning to mostly keep doing this, and might expand this practice by distilling my notes regularly (weekly? monthly?) into top-level posts
In 2025 I've decided I want to be more agentic / intentional about my life, i.e. my actions and habits should be more aligned with my explicit values.
A good way to do this might be the '5 whys' technique; i.e. simply ask "why" 5 times. This was originally introduced at Toyota to diagnose ultimate causes of error and improve efficiency. E.g:
There is a piece of broken-down machinery. Why? -->
There is a piece of cloth in the loom. Why? -->
Everyone's tired and not paying attention.
...
The culture is terrible because our boss is a jerk.
In his book on productivity, Ali Abdaal reframes this as a technique for ensuring low-level actions match high-level strategy:
Whenever somebody in my team suggests we embark on a new project, I ask ‘why’ five times. The first time, the answer usually relates to completing a short-term objective. But if it is really worth doing, all that why-ing should lead you back to your ultimate purpose... If it doesn’t, you probably shouldn’t bother.
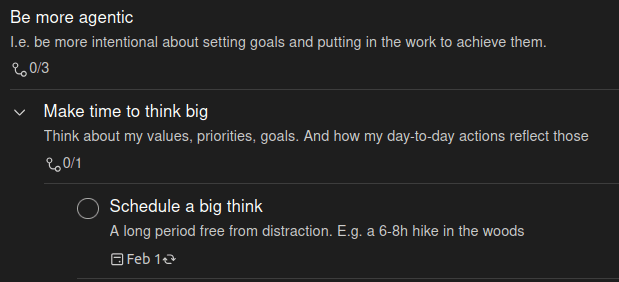
A simple implementation of this can be with nested tasks. Many todo-list apps (such as Todoist, which I use) will let you create nested versions of tasks. So high-level goals can be broken down into subgoals, etc. until we have concrete actionables at the bottom.
Here's an example from my current instantiation of this:
In this case I created this top-down, i.e. started with the high-level goal and broke it down into substeps. Other examples from my todo list are bottom-up, i.e. they reflect things I'm already intending to do and try to assign high-level motives for them.
At the end of doing this exercise I was left with a bunch of high-level priorities with insufficient current actions. I instead created todo-list actions to think about whether I could be adding more actions. I was also left with many tasks / plans I couldn't fit into any obvious priority. I put these under a 'reconsider doing' high-level goal instead.
Overall I'm hoping this ~1h spent restructuring my inbox will pay off in terms of improved clarity down the line.
In the absence of ground-truth verifiers, the foundation of modern frontier AI systems is human expressions of preference (i.e 'taste'), deployed at scale.
Gwern argues that this is what he sees as his least replaceable skill.
The "je ne sais quois" of senior researchers is also often described as their ‘taste’, i.e. ability to choose interesting and tractable things to do
Even when AI becomes superhuman and can do most things better than you can, it’s unlikely that AI can understand your whole life experience well enough to make the same subjective value judgements that you can. Therefore expressing and honing this capacity is one of the few ways you will remain relevant as AI increasingly drives knowledge work. (This last point is also made by Gwern).
A handle is a short, evocative phrase or sentence that triggers you to remember the knowledge in more depth. It’s also a shorthand that can be used to describe that knowledge to other people.
I believe this is an important part of the practice of scalably thinking about more things. Thoughts are ephemeral, so we write them down. But unsorted collections of thoughts quickly lose visibility, so we develop indexing systems. But indexing systems are lossy, imperfect, and go stale easily. To date I do not have a single indexing system that I like and have stuck to over a long period of time. Frames and mental maps change. Creative thinking is simply too fluid and messy to be constrained as such.
The best indexing system is your own memory and stream of consciousness - aim to revisit ideas and concepts in the 'natural flow' of your daily work and life. I find that my brain is capable of remembering a surprising quantity of seemingly disparate information, e.g. recalling a paper I've read years ago in the flow of a discussion. It's just that this information is not normally accessible / requires the right context to dredge up.
By intentionally crafting short and meaningful handles for existing knowledge, I think it's possible to increase the amount of stuff you can be thinking concurrently about many times over. (Note that 'concurrent' here doesn't mean literally pursuing many streams of thoughts at the same time, which is likely impossible. But rather easily switching between different streams of thought on an ad-hoc basis - like a computer processor appearing to handle many tasks 'concurrently' despite all operations being sequential)
Crafting good handles also means that your knowledge is more easily communicable to other people, which (I claim) is a large portion of the utility of knowledge.
The best handles often look like important takeaway insights or implications. In the absence of such, object level summaries can be good substitutes
See also: Andy Matuschak's strategy of writing durable notes.
Shower thought: Imposter syndrome is a positive signal.
A lot of people (esp knowledge workers) perceive that they struggle in their chosen field (impostor syndrome). They also think this is somehow 'unnatural' or 'unique', or take this as feedback that they should stop doing the thing they're doing. I disagree with this; actually I espouse the direct opposite view. Impostor syndrome is a sign you should keep going.
Claim: People self-select into doing things they struggle at, and this is ultimately self-serving.
Humans gravitate toward activities that provide just the right amount of challenge - not so easy that we get bored, but not so impossible that we give up. This is because overcoming challenges is the essence of self-actualization.
This self-selection toward struggle isn't a bug but a feature of human development. When knowledge workers experience impostor syndrome or persistent challenge in their chosen fields, it may actually indicate they're in exactly the right place for growth and self-actualization.
Implication: If you feel the imposter syndrome - don't stop! Keep going!
I’m pretty confused as to why it’s become much more common to anthropomorphise LLMs.
At some point in the past the prevailing view was “a neural net is a mathematical construct and should be understood as such”. Assigning fundamentally human qualities like honesty or self-awareness was considered an epistemological faux pas.
Recently it seems like this trend has started to reverse. In particular, prosaic alignment work seems to be a major driver in the vocabulary shift. Nowadays we speak of LLMs that have internal goals, agency, self-identity, and even discuss their welfare.
I know it’s been a somewhat gradual shift, and that’s why I haven’t caught it until now, but I’m still really confused. Is the change in language driven by the qualitative shift in capabilities? do the old arguments no longer apply?
I'm worried that it will be hard to govern inference-time compute scaling.
My (rather uninformed) sense is that "AI governance" is mostly predicated on governing training and post-training compute, with the implicit assumption that scaling these will lead to AGI (and hence x-risk).
However, the paradigm has shifted to scaling inference-time compute. And I think this will be much harder to effectively control, because 1) it's much cheaper to just run a ton of queries on a model as opposed to training a new one from scratch (so I expect more entities to be able to scale inference-time compute) and 2) inference can probably be done in a distributed way without requiring specialized hardware (so it's much harder to effectively detect / prevent).
Tl;dr the old assumption of 'frontier AI models will be in the hands of a few big players where regulatory efforts can be centralized' doesn't seem true anymore.
Are there good governance proposals for inference-time compute?
Here's how I explained AGI to a layperson recently, thought it might be worth sharing.
Think about yourself for a minute. You have strengths and weaknesses. Maybe you’re bad at math but good at carpentry. And the key thing is that everyone has different strengths and weaknesses. Nobody’s good at literally everything in the world.
Now, imagine the ideal human. Someone who achieves the limit of human performance possible, in everything, all at once. Someone who’s an incredible chess player, pole vaulter, software engineer, and CEO all at once.
Basically, someone who is quite literally good at everything.